Onomastic Home
Welcome to the main resource page of the Cornish National Onomastics Research Group for students and researchers. Most of the resources below are hosted by other organisations who provide important tools and techniques for the digital humanities, linguists, and historians.
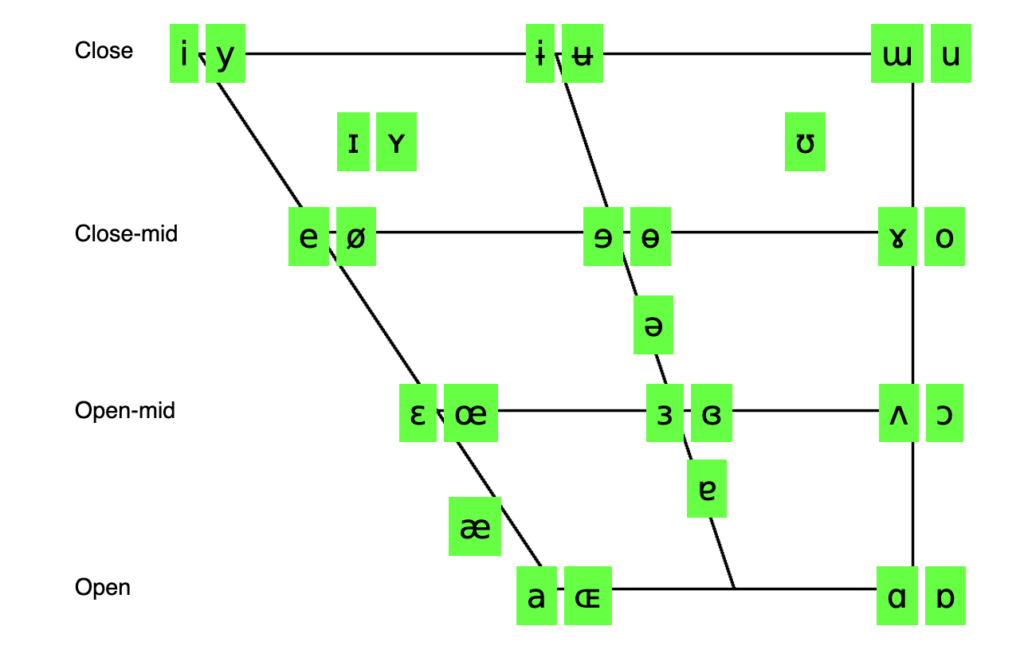
An IPA chart for both vowels and consonants, with sound files for each phoneme.

https://qgis.org/en/site/about/index.html
Quantum GIS site including download page. QGIS is an open source geographical information system with plugins for map creation, rendering, overlays and maths functions.
https://www.exeter.ac.uk/research/digitalhumanities/
This is the Exeter Digital Humanities landing page and site.
https://www.exeter.ac.uk/research/centres/ics/
This is the Institute of Cornish Studies landing page and site.
https://geiriadur.uwtsd.ac.uk/
An online Welsh-English, English-Welsh dictionary.
https://www.cornishdictionary.org.uk/?locale=en
An online Cornish-English, English-Cornish dictionary.
An online Breton-English, English-Breton dictionary.